Mi ez?
Az Observable tkp. olyan mint a Promise, de nem része a JavaScript szabványnak. Az Observable szó azt jelenti, hogy ‘megfigyelhető‘, azaz egy olyan objektum, amelyik folyamatosan változik és meg lehet figyelni, és az alkalmazás különböző pontjain különböző megfigyelők iratkozhatnak fel rá.
- lehet több megfigyelő
- az esemény bekövetkeztéről mindenki könnyen értesülhet
- az eseményeket mint adatfolyamot kezeljük
- lehet manipulálni (pl. filter, map)
- mellékhatásokat tudunk vele kiváltani (pl. kiiratjuk az értéket a konzolra)
A reaktív programozás
A következő szövegek forrása: Horváth Győző – Móger Tibor László: Webes környezet aszinkron kódjainak elemzése, refaktorálása
„A program állapotát deklaratívan az adatfolyamok közötti kapcsolatokkal írjuk le, így ha egy adatfolyamon valamilyen változás következik be, akkor az az egész rendszeren végigterjedve változásokat idézhet elő, ha a megfelelő függőségek léteznek”. Azaz attól reaktív, hogy ha az adatfolyamon változás következik be, akkor az reakciók sorozatán terjed tovább az egész rendszeren.
A reaktív programozás egy programozási paradigma. „Az elve, hogy az adatokat egyszerű változók helyett adatfolyamokban tároljuk, amelyek időben változhatnak. … Egy gyakran használt példa a reaktív programozás szemléltetésére a dupla kattintások kezelése. A dupla kattintást definiálhatjuk úgy, hogy két kattintás között, közel ugyanazon a pozíción kevesebb, mint fél másodperc telik el. Egy dupla kattintás esetén szeretnénk a duplán kattintott elem pozícióját kiírni a képernyőre. Egy nem reaktív megoldás pontosan az ezt megvalósító kódot írná le egy eseménykezelőben. Minden „első” kattintás esetén eltárolná az aktuális eseményt, beállítana egy időzítőt, ami a fél másodperc letelte után eltávolítaná az „első” eseményt. Ha még azelőtt beérkezik egy újabb esemény, hogy ez megtörténne, akkor az új kattintás már „második” kattintásnak minősül, tehát ez egy dupla klikk volt, ekkor pedig meghívja a képernyőre kiíró függvényt. Ez a megoldás nem túl reaktív, például adatfolyamok egyáltalán nem jelennek meg benne. „
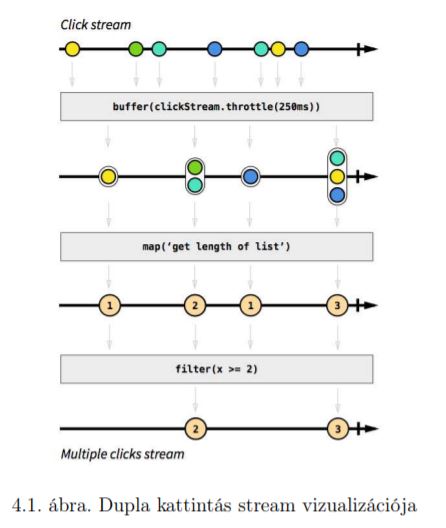 „Egy reaktívabb megoldás lenne, ha a dupla kattintásokat egy adatfolyamként definiálnánk, és erre feliratkozva írnánk ki a képernyőre az adatokat. … Erre egy jó leíró eszköz a Reactive extensions. Ebben az eszközben a fenti példa valahogy úgy működne, hogy létezik egy adatfolyamunk a kattintásokról. Erre az adatfolyamra rárakunk egy olyan megfigyelőt, aki minden „első” esemény esetén bufferelni kezdi az adott időablakon belül beérkező eseményeket, majd egy olyan adatfolyamként testesül meg, ami az első események után lejárt időablak végén bocsát ki magából adatokat, és ebben az időablakban megjelent eseményeket buffereli. A következő megfigyelőnk megszámolná, hogy hány esemény lett bufferelve, és ezt bocsátaná ki magából. További megfigyelőkkel pedig leszűrnénk ezt az adatfolyamot a kettőnél több kattintást tartalmazó időablakokra, és az egymáshoz közeli kattintásokra. A végül előállt adatfolyamunkra pedig egy imperatív feliratkozáson keresztül létrehozunk egy reakciót, ami kiírja a felületre a kattintott elem pozícióját. Ez rendkívül körülményesnek tűnhet, de a megfelelő absztrakciók jelenlétében egy jól olvasható deklaratív megoldást ad.”
„Egy reaktívabb megoldás lenne, ha a dupla kattintásokat egy adatfolyamként definiálnánk, és erre feliratkozva írnánk ki a képernyőre az adatokat. … Erre egy jó leíró eszköz a Reactive extensions. Ebben az eszközben a fenti példa valahogy úgy működne, hogy létezik egy adatfolyamunk a kattintásokról. Erre az adatfolyamra rárakunk egy olyan megfigyelőt, aki minden „első” esemény esetén bufferelni kezdi az adott időablakon belül beérkező eseményeket, majd egy olyan adatfolyamként testesül meg, ami az első események után lejárt időablak végén bocsát ki magából adatokat, és ebben az időablakban megjelent eseményeket buffereli. A következő megfigyelőnk megszámolná, hogy hány esemény lett bufferelve, és ezt bocsátaná ki magából. További megfigyelőkkel pedig leszűrnénk ezt az adatfolyamot a kettőnél több kattintást tartalmazó időablakokra, és az egymáshoz közeli kattintásokra. A végül előállt adatfolyamunkra pedig egy imperatív feliratkozáson keresztül létrehozunk egy reakciót, ami kiírja a felületre a kattintott elem pozícióját. Ez rendkívül körülményesnek tűnhet, de a megfelelő absztrakciók jelenlétében egy jól olvasható deklaratív megoldást ad.”
Reactive extensions
„A reaktív programozásnak az egyik implementációja az úgynevezett Reactive extensions (Rx), amely egy nyelveket átívelő interfész annak a kifejezésére, hogy hogyan lehet jól reaktív programokat leírni. Ez egy push alapú, szükség esetén aszinkron, lusta implementáció. Most nézzük meg jobban, hogy mit értünk ez alatt.
- A push alapú azt jelenti, hogy az egy adatfolyamra feliratkozók akkor kapnak adatokat, ha az eredeti adatfolyamon megjelenik egy adat. Ennek ellentéte a pull alapú lehetne, ami viszont azt jelentené, hogy az eredeti adatfolyamnak akkor kell adatot szolgáltatnia, amikor a feliratkozó azt kéri tőle.
- A szükség esetén aszinkron alatt azt kell érteni, hogy ha folyamokon elhelyezett adatfolyamként megfigyelhető feliratkozóknak áll rendelkezésre adat, akkor azt szinkron dolgozzák fel, de ha nincs ilyen, akkor várakoznak.
- A lustaság alatt itt azt kell érteni, hogy ha nincs imperatív feliratkozója egy adatfolyamnak, akkor hiába push alapú a rendszer, az alul levő adatfolyamon nem jelennek meg értékek, vagy azokat nem dolgozzuk fel. Ez alól majd kivételt jelentenek a hot streamek, ahol az adatfolyam olyan, mintha lenne imperatív feliratkozója, de ilyen valójában nincs.”
A tulajdonságokat követően nézzük az Rx építőköveit:
- Observable: Ezek felelnek meg az adatfolyamoknak.
- operátorok: Az operátorok segítségével adatfolyamok közötti transzformációkat tudunk megvalósítani. Operátor lehet például egy adatfolyam megszűrése, megszorzása kettővel, időablakokra osztása, késleltetése, aggregálása. Az operátorok általában egy observable-t várnak paraméterül, és egy observable-t adnak vissza. Ennek előnye, hogy az operátorokat tudjuk láncolni, így kényelmesen egy bonyolultabb adatfolyam átalakítást le tudunk írni operátorok kompozíciójaként.
- Subscriber/Subscription: Egy observable-re feliratkozhatunk a subscribe metódusuk segítségével. Ha ez egy cold observable, akkor ezzel tudjuk aktiválni a működését. Az adatfolyamok utolsó láncszemeként megjelenő adatfolyamokra itt lehet mellékhatásokat elhelyezni. Egy feliratkozás létrehoz egy Subscription objektumot, ami életben tudja tartani az adatfolyamot, ezért ha az adatfolyam nem fejeződött be akkor, amikor már nincs rá szükségünk, akkor ezeket pusztítsuk el.”
RxJS
„A JavaScript világban az RxJS könyvtár adja ezeket az Rx által leírt eszközöket. … Az RxJS nem szervesen a JavaScript nyelv része, habár voltak erőfeszítések arra,
hogy az alapjait támogassák a nyelv szintjén a futtatókörnyezetek. Ennek ellenére
ez is egy eszköz az aszinkronitás kezelésére.”
(Forrás – Horváth Győző – Móger Tibor László: Webes környezet aszinkron kódjainak elemzése, refaktorálása)
RxJS használata – operátorok
RxJS betöltése CDN-ről: <script src=”https://unpkg.com/rxjs@^7/dist/bundles/rxjs.umd.min.js”></script>
Példakód npmjs.com-ról:
const { range } = rxjs;
const { map, filter } = rxjs.operators;
range(1, 200)
.pipe(
filter(x => x % 2 === 1),
map(x => x + x)
)
.subscribe(x => console.log(x));
Kétféle operátor van. A Creation Operators, amelyek egy új Observable-t hoznak létre, ill. a Pipeable Operators, amelyek tkp. – az observableInstance.pipe(operator()) szintaxissal használható – metódusok, s módosítják a Observablet, de nem az eredeti Observable-t írják felül, hanem egy új Observable-vel térnek vissza.
A fenti példában a range(start: number, count: number) operátor fogja létrehozni az Observable-t, ami tkp. maga a stream, az adatfolyam. Paraméterei:
- start: ez lesz a számsorozat első egész értéke, s innentől kezdve növekednek a kibocsátott , amíg el nem érik a count-ban megadott darabszámot. Opcionális, default értéke a nulla.
- count: ennyi értéket fog kibocsátani
A példában pedig két pineaple operátor a filter és a map, amelyek ugyanúgy működnek, mint az azonos nevű tömb metódusok. A filter itt leválogatja a páratlan számokat, a map pedig mindegyiket megduplázza.
const { of } = rxjs;
const { map } = rxjs.operators;
of(1, 2, 3)
.pipe(map((x) => x * x))
.subscribe((v) => console.log(`value: ${v}`));
Ebben a példában (rxjs.dev) az of(1,2,3) létrehozza azt az Observablet, amely az 1, 2, 3 értékeket bocsátja ki egymás után. A map metódus mindegyiknek veszi a négyzetét, majd a subscribe operátorral feliratkozunk az utoljára kibocsátott stream-re, s ezt kapjuk a konzolon: 1, 4, 9.
Operátorokról részletesen: rxjs.dev, ill. javatpoint.com.